【大紀元2020年05月03日訊】中共病毒(武漢肺炎或COVID-19)自武漢爆後蔓延至187個國家,目前造成超過300萬人感染、24萬人死亡。全球感染和死亡人數不斷攀升之際,中共卻發出幾乎零增長的數據。病源國的數據對於各國研究病毒、研發疫苗、採取防範措施起著至關重要的作用,因此病源國數據的可靠、全面就極為關鍵。因此各國的各領域專家、學者在分析疫情數據中不斷尋求答案。4月21日,彭堯好博士發布了一項研究報告,運用數學分析發現,中共政府提供的疫情數據有眾多異常之處,引人思考。
彭堯好曾獲巴西利亞大學金融管理博士學位,主要研究數據分析和數學預測模型。彭博士及團隊近期對中共政府提供的官方COVID-19(中共病毒)數據進行分析,並運用統計學與其它疫情嚴重國家的數據進行了比較,結果顯示大多數國家的數據相互之間近似,且基本都符合「本福德定律」(Benford’s Law),唯有中國的數據模式與其它所有國家都截然不同。
本福德定律常被用於檢測數據造假。彭博士等學者還運用了假設檢驗再次輔證了上述的研究結果。
首先,研究報告指出,在研究流行病數據中,感染病例和死亡人數會呈指數增長,尤其是在疾病的早期階段。而社會隔離的措施會減少高峰期受影響的人數,在時間線上延長「浪波」,試圖「拉平曲線」,但需要一個過程。
影響數據走向的因素很多,比如各國領土面積、人口密度、溫度、季節、漏報的程度、遵守隔離措施的嚴格程度、防範措施實行的及時與否等方面的差異都會造成各國數據之間的不同。但據研究報告指出,病毒自中國出現以來尚未發生根本性突變,傳染性和致死性的相對比例在各國之間應該是相似的。而中共政府提供的數據顯示出與其它地區完全不同的數據特征。具體表現在以下方面:
數據曲線走向與規律相悖
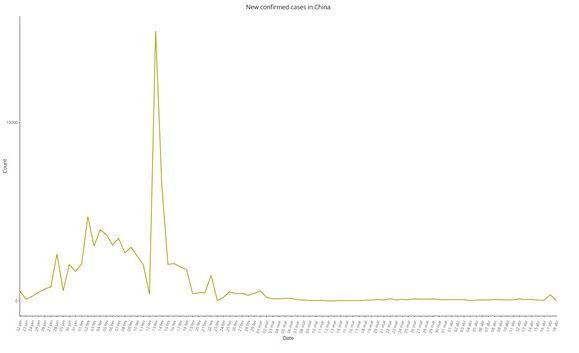
研究指出,中共提供的數據顯示,指數增長模式出現在疫情早期,但曲線的變化率迅速降低,這與預期和幾乎所有其它國家所觀察到的規律相悖。
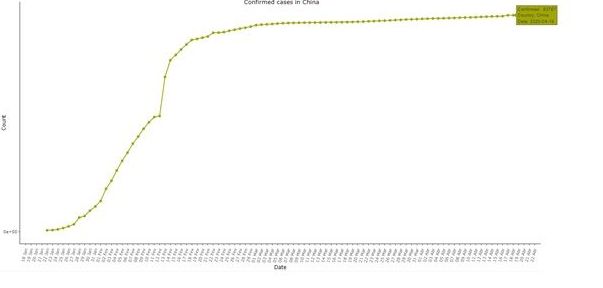
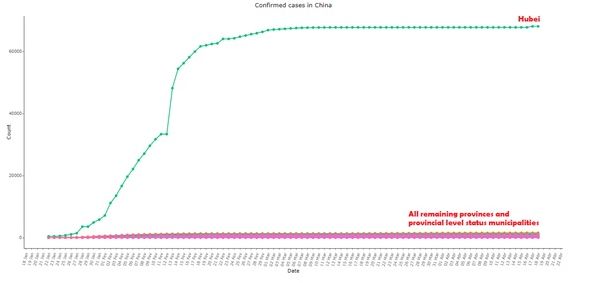
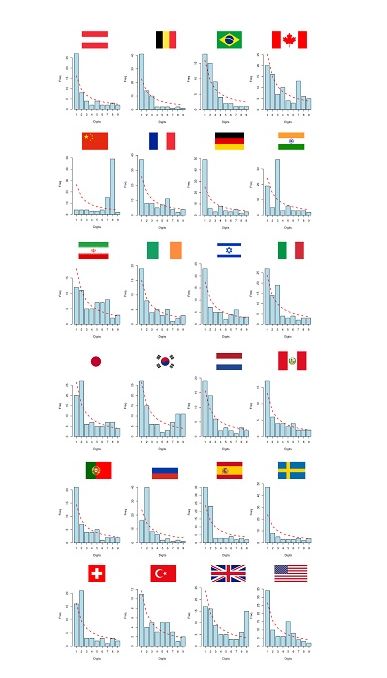
圖1和圖2中顯示,早期受感染人數激增,呈現接近直線的趨勢,之後出現單天內激增,這在傳染病中是很鮮見的。之後又長期幾乎沒有變化,自三月初以來幾乎是一條直線。研究認為這些都是非常罕見的現象。
湖北一省和全中國數據圖近乎完全相同
特別值得注意的是,研究報告指出,通過查看「趨勢圖」中省級匯總數據的分解,可以發現,湖北省與全中國的疫情數據圖近乎完全相同。(參見圖1和圖3)。
中國各省曲線幾乎同一模式
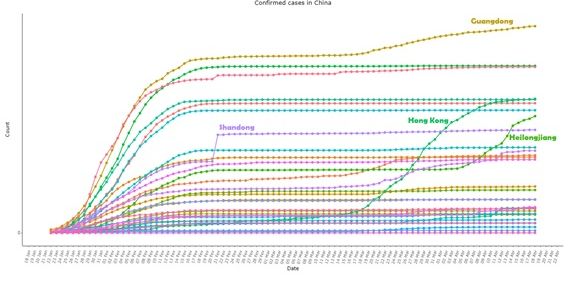
研究報告顯示,查看圖4發現,即使各省之間在人口密度、溫度、與病毒發源地武漢的距離等存在巨大差異,但是幾乎所有省份(不包括台灣),呈現出與湖北、中國整體幾乎相同的模式——形成驚人的輪廓準確的S型曲線。
研究還指出,在中國、湖北省出現異常高峰的同一天,也就是2月11—12日,中共湖北省委書記蔣超良和湖北省委副書記馬國強被免職。山東省單在2020年2月21日一天就出現「陡峭」的變化,該日濟寧市任城監獄恰好報告了該病毒的爆發,當天證實的統計數字增加了203人。報告還指出,除這天之外,所有時段內曲線均表現「很聽話」。
與各國疫情曲線走向不同
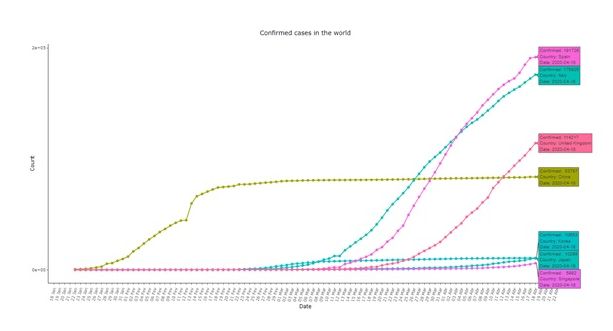
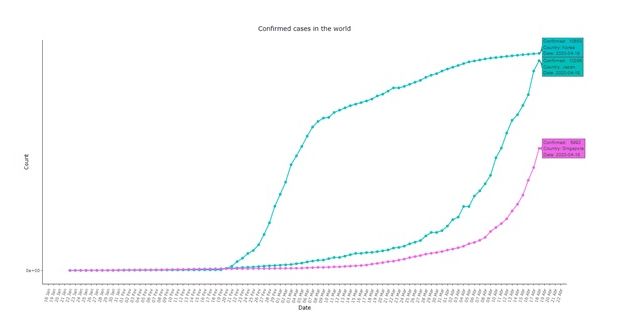
在微積分中有個概念,指數函數的導數也是指數函數。依次可以預測確診病例的每日變化也應遵循指數增長,各國數據都基本符合,而中共政府提供的數據卻顯示出完全不同的表現。死亡數據曲線也不例外。
研究指出,採取嚴格的隔離、社交疏離措施將直接影響曲線的形狀。但是,至少在初始階段指數模式仍會被保留,這些措施的效果也需一段時間才能顯現出來。研究還對疫情較為嚴重國家的數據進行了比較。包括日本、新加坡和韓國(對病毒做出早期反應的國家)以及意大利、西班牙和英國(僅在更晚期階段才反映得更加強烈的國家)。各國基本都在疫情早期或晚期出現了指數增長。
不符合「本福德定律」
本福德定律常被用於檢測數據造假。研究報告指出,根據本福德定律來檢測中共政府提供的患病和死亡數據,發現了同樣的問題,所有國家的曲線都基本符合該定律,只有中共的數據與定律的規律大相逕庭(參見圖7)。
我們用個例子了解本福德定律。如果統計世界上237個國家的人口數量,一般都會覺得以1和9開頭的數會分別占1/9的比例,而實際上,以1開頭的數占約1/3,其次是2,再次是3,以此類推,數字越大所占比例越小,9開頭的數字占5%。
神奇的本福德定律(又稱班佛定律)適用於幾乎所有自然生成的統計數據,如人口數量、國土面積、財務報表、銷售數據等。而人造數據則不符合該定律,所以被廣泛用於檢查數據庫中的造假行為。
但並非所有數據都可用該定律進行分析。首先,滿足本福德定律的數據必須是自然生成的,不能經過人為規則的設定和限制。像身分證號、電話號碼、發票編號等這些數據就不適用;第二,數據的跨度需要夠大,數量級越大越符合本福德定律(如100,1000,10000,100000,…)。彭博士舉例說,那些有上下限的數據,比如年齡、身高、體重就不滿足這個定律;再有就是人為刻意編造修改的數據,比如美國最大的能源交易商安然公司的假帳數據。當年經查,每股盈利數據不符合本福德定律,發現有造假行為,安然公司最終宣布破產。
彭博士在研究報告最後提到,儘管中國是病毒的發源地,但考慮到其數據與其它地區的數據之間存在的巨大差異,應格外謹慎使用中共提供的數據來研究中共病毒(COVID-19)的參數(如基本傳染數、死亡率等),病毒傳染的地理蔓延法規、干預方案的有效性等其它分析。
英文原文:Statistical analysis of the Chinese COVID-19 data with Benford’s Law and clustering.
責任編輯:周儀謙 #